Меньше драмы: искусственный интеллект в России есть, и у него всё хорошо
Интервью с Игорем Беляком, Directum
Рынок искусственного интеллекта в нашей стране переживает самый настоящий Ренессанс. Наблюдается активный рост по всем направлениям. Увеличилась господдержка ИИ-инициатив, выросло число AI-стартапов, появилась самая большая российская мультимодальная модель генерации картинок по тексту (Kandinsky), принят Кодекс этики в сфере искусственного интеллекта. Под последним подписалась и компания Directum.
Игорь Беляк, директор направления по искусственному интеллекту компании Directum, рассказал, как высоко он оценивает позиции ИИ в России, что понимает под «искусственным интеллектом» и почему считает, что ИТ-продукт должен дообучаться прямо в процессе своей работы.
Куда идет отечественный ИИ
— Игорь, что сейчас происходит с рынком интеллектуального ПО в России?
Лучше всего на этот вопрос ответят цифры. По данным отчета AI Report, в 2021 году рынок искусственного интеллекта в нашей стране составлял 550 млрд руб. Причем основной сегмент рынка — это анализ данных, NLP и цифровые помощники. По сравнению с 2020-м рынок ИИ вырос на 28%. По прогнозам того же AI Report, в 2023-2024 годах рост сохранится.
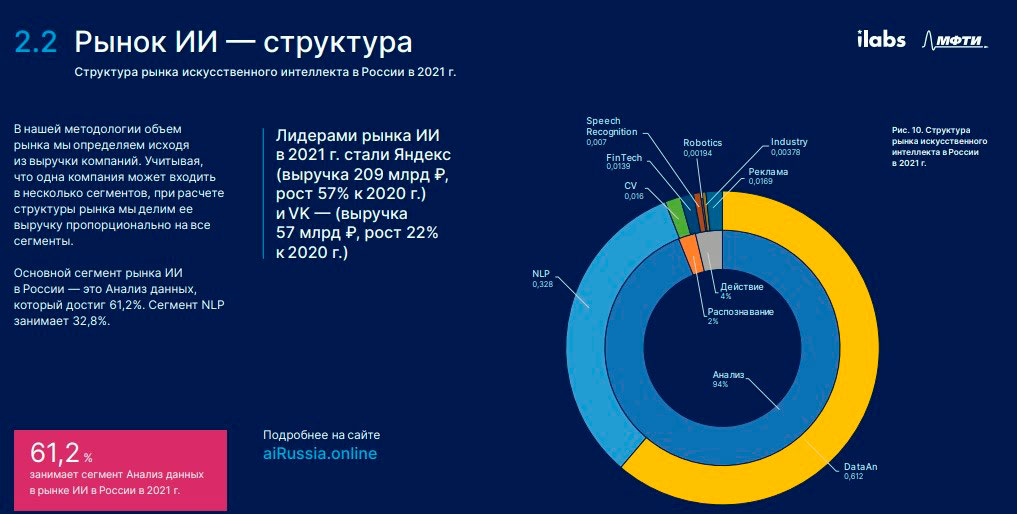 Альманах «Искусственный интеллект» Индекс-2021
Альманах «Искусственный интеллект» Индекс-2021
Приведу в пример еще одно авторитетное исследование. В 2019 году Министерство цифровизации РФ выпустило дорожную карту развития «сквозной» цифровой технологии «Нейротехнологии и искусственный интеллект», в рамках которой также спрогнозировало рост рынка ИИ — до 107,2 млрд руб. в 2023 году и до 160,1 млрд руб. в 2024-м.
При развитии интеллектуального ПО мы в компании Directum ориентируемся в том числе на эту дорожную карту. Могу сделать вывод, что потенциальный объем и емкость рынка для продукта Directum RX Intelligence составит 32,8% или 180 млрд руб.
— Какую роль играет компания Directum в развитии технологий искусственного интеллекта в России?
Хочется верить, что сейчас мы в числе пионеров развития ИИ в сфере обработки корпоративного контента. В далеком 2018 году мы и несколько других компаний были первопроходцами в освоении ИИ. Сегодня Directum RX — официально первая российская интеллектуальная система в классе СЭД в классах «06.12 Программное обеспечение средств электронного документооборота» и «04.08 Интегрированные платформы для создания приложений».
Что такое искусственный интеллект в России

— Есть официальная трактовка того, что считать искусственным интеллектом. Согласно дорожной карте развития технологии «Нейротехнологии и искусственный интеллект» ИИ — это комплекс технологических решений, имитирующий когнитивные функции человека и позволяющий при выполнении задач достигать результаты, как минимум сопоставимые с результатами интеллектуальной деятельности человека. Насколько искусственный интеллект в составе Directum RX соответствует этому определению?
Периодически возникают споры на тему того, что ИИ не существует, а те продукты, которые сейчас есть на рынке, якобы просто нейросеть под маркетинговым соусом. Хочу раз и навсегда развеять этот миф.
В ГОСТ Р 59277-2020. Классификация систем искусственного интеллекта дается четкое определение, что такое ИИ:

ИИ в составе Directum RX Intelligence полностью соответствует этому определению, и вот доказательства:
- В нашем продукте применяются механизмы, которые позволяют имитировать когнитивные функции человека. Например, чтение (компьютерное зрение — CV), распознавание образов (компьютерное зрение — CV), классификация объектов (компьютерное зрение — CV, обработка естественного языка — NLP) и т.д.
- ИИ-механизмы самообучаются и дообучаются в процессе использования системы Directum RX.
- Для классификации документов не нужно вручную задавать четкий алгоритм системе, какой документ к какому классу относить. Мы просто показываем ей примеры, а она сама формирует этот алгоритм с помощью машинного обучения и нейросетевых моделей. Аналогично и с извлечением фактов. Пример такого алгоритмического подхода к обработке документов — извлечение фактов на правилах и поиск печатей.
- Теперь что касается получения результатов, сопоставимых, как минимум, с результатами интеллектуальной деятельности человека. Разберу утверждение на примере практически значимой задачи — извлечения фактов из документов. Является ли для человека понимание сути, структуры и отдельных фактов в документе интеллектуальной деятельностью? Безусловно, так как эта задача требует обучения, погружения в предметную область и практики. Да, задача рутинная, но точно не неинтеллектуальная. Нельзя требовать от неподготовленного человека, чтобы он корректно извлек все необходимые факты из документа.
И еще одна важная ремарка. В гостовском определении не говорится о том, что искусственный интеллект должен полностью повторять когнитивные функции человека. Его задача — только и м и т и р о в а т ь человеческие зрение, слух, понимание, анализ данных, принятие решений. С этой точки зрения наша система соответствует термину государственных стандартов, действующих в Российской Федерации.
Зачем интеллектуальной системе дообучаться

— Хорошо, с вопросом ИИ-идентификации разобрались. А что скажете по поводу уникальных характеристик — обладает ли Directum RX особой функциональностью, которая отличает его от подобных продуктов на рынке РФ?
Еще раз замечу, что кроме Directum RX Intelligence, в России сейчас нет других систем для управления корпоративным контентом и бизнес-процессами, в состав которых так глубоко встроен искусственный интеллект.
Наша команда планирует реализовать функциональность дообучения интеллектуальных механизмов на исторических данных непосредственно в процессе работы. Уже разработана модель извлечения фактов — ансамбль однофактовых моделей, которая уберет технологические ограничения для автоматического дообучения. Что это даст нашим клиентам?
- не нужно вручную создавать модели;
- быстрый старт даже при отсутствии исторических данных (нет данных для разметки) — модели обучаются самостоятельно по мере накопления информации в интегрируемой системе;
- не потребуются дополнительные платные адаптации продукта в случае изменения форм документов (например, при актуализации законодательства или смены ПО у контрагентов);
- нет необходимости обучать специалистов для настройки форм, определений в стороннем продукте;
- постоянное автоматическое фоновое совершенствование моделей извлечения фактов и классификации, которое повышает уровень автоматизации процессов и увеличивает ROI в Directum RX
А вишенка на торте для наших клиентов — дополнительные налоговые льготы от государства при внедрении продуктов с использованием искусственного интеллекта.
— Расскажите подробнее об ансамбле однофактовых моделей. В чем ее уникальность?
Это такой подход в извлечении фактов, который исключает этап верификации авторазмеченных документов. В случае, если в документе мы не нашли необходимый факт, то он просто не попадет в выборку, но может быть использован для обучения моделей других фактов, которые механизм авторазметки в нем нашел. Таким образом, мы делаем возможным автоматическое дообучение моделей ОИФ (обучаемое извлечение фактов). Дополнительное преимущество заключается в том, что для добавления возможности извлечения дополнительного факта к существующей модели нам необходимо в новых документах разметить только этот факт, так как модели других фактов не будут дообучаться на этих документах.
— Насколько дорого клиенту обойдется дообучение моделей?
По-разному. Весомое преимущество нашего подхода — это возможность дообучения на обычных серверных мощностях (минимальные требования: 4 ядра CPU, 20 Gb оперативной памяти). Получается, клиенту не нужно вкладываться материально.
Чаще всего решения по распознаванию и извлечению фактов из документов реализованы на сложных нейросетевых моделях, для обучения которых требуются большие вычислительные ресурсы и специальные устройства (GPU, TPU). Это либо усложняет, либо делает невозможным реализацию дообучения моделей в контуре клиента, либо существенно удорожает стоимость владения продуктом.
— Какие технологии дообучения наиболее перспективны и почему? Какие из них используете в Directum RX Intelligence?
В рамках задачи по извлечению фактов из документов мы используем три подхода, доказавших свою эффективность и применимость в продуктивной среде:
-
Механизм гибких форм — ручная разметка якорных текстовых элементов и создание правил взаимного расположения элементов. Плюс в том, что можно быстро настроить систему (достаточно 3-5 документов) под работу с хорошо структурированными документами.Недостатки же заключаются в том, что при изменении формы, якорных слов или нарушении взаимного расположения элементов необходимо выполнять ручную донастройку форм под новые формы документов. Также этот подход чувствителен к качеству текстового слоя. А у неструктурированных документов (входящие письма, обращения граждан, постановления судебных приставов и т.д.) как раз-таки качество часто страдает.
-
Гибридный механизм гибких форм и нейросетевых моделей — ручная разметка якорных элементов изображений документов и создание правил их взаимного расположенияПлюсы подхода — потребность в небольшом количестве обучающих примеров. Нейросетевые технологии компьютерного зрения помогают более гибко настраивать правила взаимного расположения объектов, ориентируясь не только на текстовый слой, но и на графические особенности документа.Недостатки аналогичны предыдущему подходу, за исключением меньшей чувствительности к качеству текстового слоя. Для того чтобы изменить форму документа, нужно вручную корректировать правила и настройки расположения и обработки тех или иных элементов.
-
Обучаемое извлечение фактов — ручная разметка фактов в документе и тренировка моделей машинного обучения.Плюсы подхода: полная независимость от формы документа, использование механизмов семантического анализа взаимосвязей в документе, возможность применения на простых текстах (не только документы), толерантность к качеству текстового слоя за счет анализа большой выборки. Разметку документов могут выполнять низкоквалифицированные сотрудники.Минус: для создания качественной модели придется разметить 400+ документов.Ключевое отличие нашего подхода ОИФ — его автоматическое дообучение. Для сравнения: все конкурентные решения на рынке адаптируются к изменяемым входных данным только через ручной режим, а это влечет дополнительные затраты и снижение эффективности работы системы.
Но дообучение ИИ-механизмов невозможно без информации о работе пользователя в системе: что он поменял, что исправил, какие документы занес и т.д. В отдельных сервисах для распознавания и извлечения фактов эти данные не хранятся, они находятся именно в корпоративной системе, в которой сотрудники работают каждый день.
Directum RX Intelligence хранит всю историю запросов пользователей и выполненных операций с документами. Благодаря глубокой интеграции системы с интеллектуальными механизмами у последних есть постоянный доступ к новым данным. За счет этого и возможно дообучение ИИ. Даже после завершения проекта внедрения система продолжает совершенствоваться и становиться умнее.
Источник: ecm-journal.ru
